
В данном цикле статей начинаем рассматривать модель Маркова, которая находит применение в задачах классификации состояния рынка и используется во многих биржевых роботах. Статьи основаны на постах, опубликованных в блоге Gekko Quant. Также будет рассмотрены практические алгоритмы на финансовых рынках. Код в цикле приведен на языке R.
Рабочая среда распознавания основных паттернов.
Рассмотрим набор признаков O, полученный из набора данных d и класс w, обозначающий наиболее подходящий класс для O:
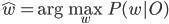
Так как 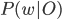 неизвестен, применяем правило Байеса:
неизвестен, применяем правило Байеса:
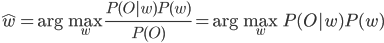
Максимизация не зависит от 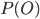 , поэтому мы можем игнорировать эту вероятность.
, поэтому мы можем игнорировать эту вероятность. 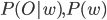 означают вероятность того, что данные O принадлежат классу w и вероятность существования класса w соответственно.
означают вероятность того, что данные O принадлежат классу w и вероятность существования класса w соответственно. 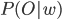 определяется моделью скрытых состояний Маркова.
определяется моделью скрытых состояний Маркова.
Формулировка задачи.
Сначала нам нужно сгенерировать набор признаков О из рыночных данных d. Пока пропустим этот шаг, потому что он будет различаться для разных применений модели Маркова, например для финансов d может быть представлен ценами разных активов и О можно обозначить набор технических индикаторов, применяемых к d. Модель Маркова также популярна в задачах распознавания речи, где О обычно является вектором, описывающим характеристики частотного спектра речи.
Затем необходимо вектор О ассоциировать с классом модели Маркова. Это можно сделать путем применения метода максимального правдоподобия, где модель Маркова определяет класс, который с наибольшей вероятностью генерирует набор параметров, соответствующий набору параметров О.
Спецификация модели Маркова.
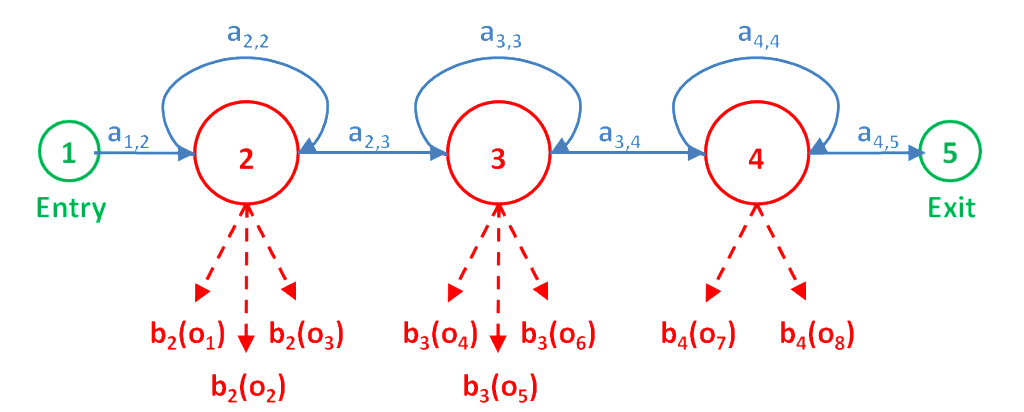
Рассмотрим рисунок в заглавии поста. На нем приведены следующие обозначения:
N - число состояний модели (на рисунке равно 5),
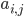 - вероятности перехода из состояния i в состояние j,
- вероятности перехода из состояния i в состояние j,
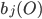 - вероятность получения вектора параметров О при состоянии j ( j не является входным и выходным состоянием),
- вероятность получения вектора параметров О при состоянии j ( j не является входным и выходным состоянием),
вектор параметров модели Маркова 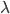 определим как
определим как ![\lambda=[N,a_{i,j},b_j]](http://www.quantalgos.ru/wp-content/plugins/latex/cache/tex_e4f8077e31978b307cbb13c56caeb948.gif) ,
,
![O=[o_1,o_2,...,o_T]](http://www.quantalgos.ru/wp-content/plugins/latex/cache/tex_c7a8c729438934377d0c82eac1e0a2c1.gif) - вектор параметров наблюдений,
- вектор параметров наблюдений,
![X=[x_1,x_2,..,x_T]](http://www.quantalgos.ru/wp-content/plugins/latex/cache/tex_53b7ec9a7520fbf7222e10eedd3f41ad.gif) - найденный вектор последовательности состояний.
- найденный вектор последовательности состояний.
Совместная вероятность соответствия вектора О последовательности состояний X при параметрах модели равна вероятности перехода из текущего состояния в следующее , умноженное на вектор параметров, сгенерированный в этом состоянии:
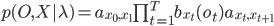
где 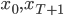 - входное состояние 1 и выходное сотояние N соответственно.
- входное состояние 1 и выходное сотояние N соответственно.
Вычисление вероятности.
В рассмотренной выше совместной вероятности мы определили последовательность состояний X. Так как эта последовательность является скрытой переменной ( вот почему модель Маркова называется моделью скрытых состояний), мы ее не знаем. Однако, если мы суммируем вероятности по всем возможным состояниям, то получим:
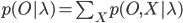
Это может быть проблематичным из-за большого числа состояний модели (особенно в приложениях реального времени), но существуют эффективные алгоритмы для такого вычисления, без нахождения каждого отдельного состояния. Подобным алгоритмом является форвардный алгоритм.
Что представляет из себя 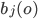 ?
?
Это полученное распределение вероятностей при состоянии j модели. Это распределение может быть любым, но оно должно соответствовать распределению данных при состоянии j, и должно быть математически определяемым. Обычным выбором на этой стадии является предположение, что вектор O может описываться набором гауссовских распределений - мультивариантным нормальным распределением. В качестве предупреждения отметим, что если составляющие вектора параметров сильно коррелированы между собой, тогда  - ковариационная матрица - будет иметь много вычисляемых значений. В этом случае нужно подбирать вектор парметров так, чтобы представляла собой диагональную матрицу, другими словами, параметры не должны быть кореллированы между собой:
- ковариационная матрица - будет иметь много вычисляемых значений. В этом случае нужно подбирать вектор парметров так, чтобы представляла собой диагональную матрицу, другими словами, параметры не должны быть кореллированы между собой:
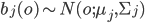 , где
, где 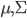 - параметры мультивариантного гауссовского распределения.
- параметры мультивариантного гауссовского распределения.
Как получить ? Определение параметров методом Витерби.
Мы знаем, что для описания нормального распределения достаточно методом максимального правдоподобия вычислить среднее распределения 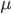 и ковариацию вектора параметров. Значит мы должны получить только среднее и ковариацию вектора параметров для состояния j нашей модели, используя так называемую сегментацию Витерби. Она подразумевает нахождения жесткого соответствия между ветором параметров и последовательностью состояний, которое его генерировало. Существует также и альтернативный метод Баума-Вельша, который ассоциирует вектор параметров с несколькими последовательностями состояний с определенной вероятностью.
и ковариацию вектора параметров. Значит мы должны получить только среднее и ковариацию вектора параметров для состояния j нашей модели, используя так называемую сегментацию Витерби. Она подразумевает нахождения жесткого соответствия между ветором параметров и последовательностью состояний, которое его генерировало. Существует также и альтернативный метод Баума-Вельша, который ассоциирует вектор параметров с несколькими последовательностями состояний с определенной вероятностью.
Состояние j генерирует наблюдения, начиная с 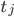 :
:
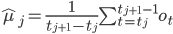
![\hat{\Sigma}_j=\frac{1}{t_{j+1}-t_j}\sum_{t=t_j}^{t_{j+1}-1}[(o_t-\hat{\mu}_j)(o_t-\hat{\mu}_j)^{`}]](http://www.quantalgos.ru/wp-content/plugins/latex/cache/tex_f4ee25f62bbe4a242ae8a11704dd0267.gif)
Наперед неизвестно, какая последовательность какой вектор наблюдений генерирует, но существует алгоритм Витерби, позволяющий решить эту проблему с некоторым приближением:
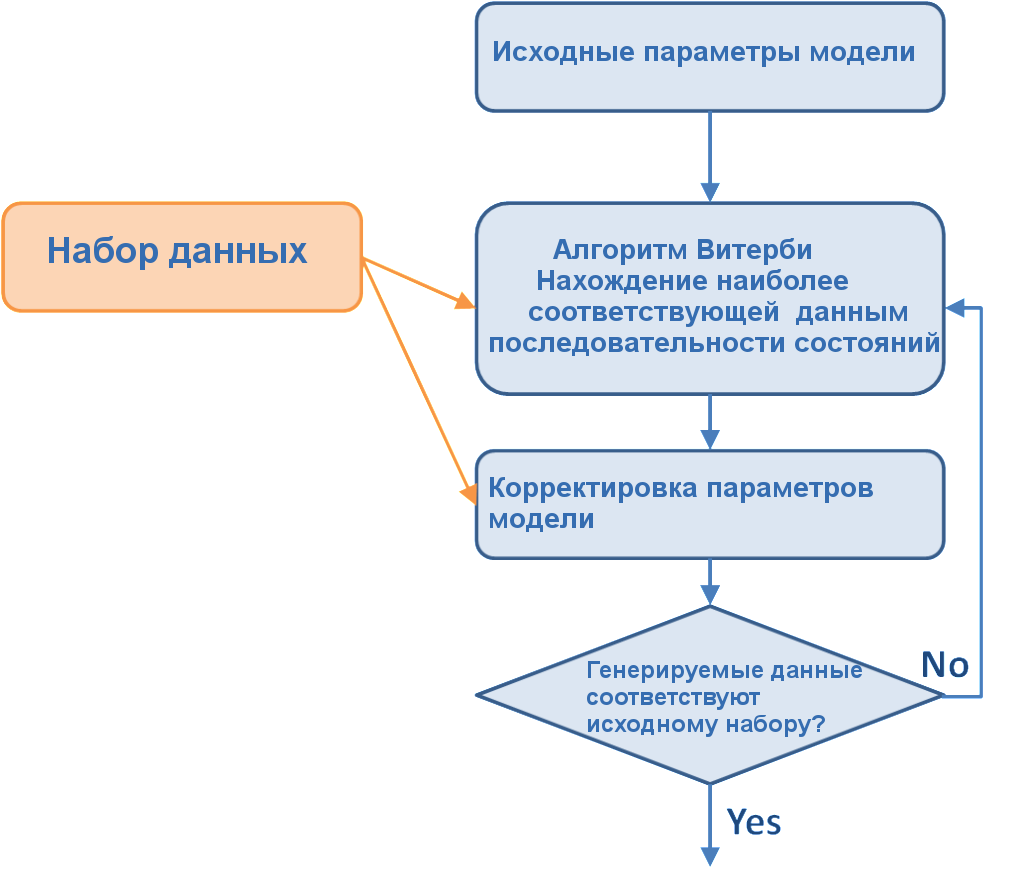 Подробно алгоритм Витерби, а также форвардный алгоритм для эффективного вычисления
Подробно алгоритм Витерби, а также форвардный алгоритм для эффективного вычисления 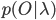 рассмотрим в следующей части.
рассмотрим в следующей части.


Интересные посты, спасибо.
Вы не могли бы вот всё то же самое описать предельно упрощенно в двух словах, без всяких формул и картинок, для понимания сути? Желательно на конкретном примере.
Что-то вроде этого: "1) признаком считаем приращение бара, 2) паттерном считаем последовательный набор определенных приращений, 3) считаем на истории среднее приращение после разных наборов, 4) видим, что после трех подряд приращений +10,+10,+10 среднее приращение следующего бара значимо отличается от нуля".
Эту фразу тоже можно развернуть в кучу формул и картинок, но это уже детали.
В последней части даны конкретные примеры, вроде должно быть все понятно