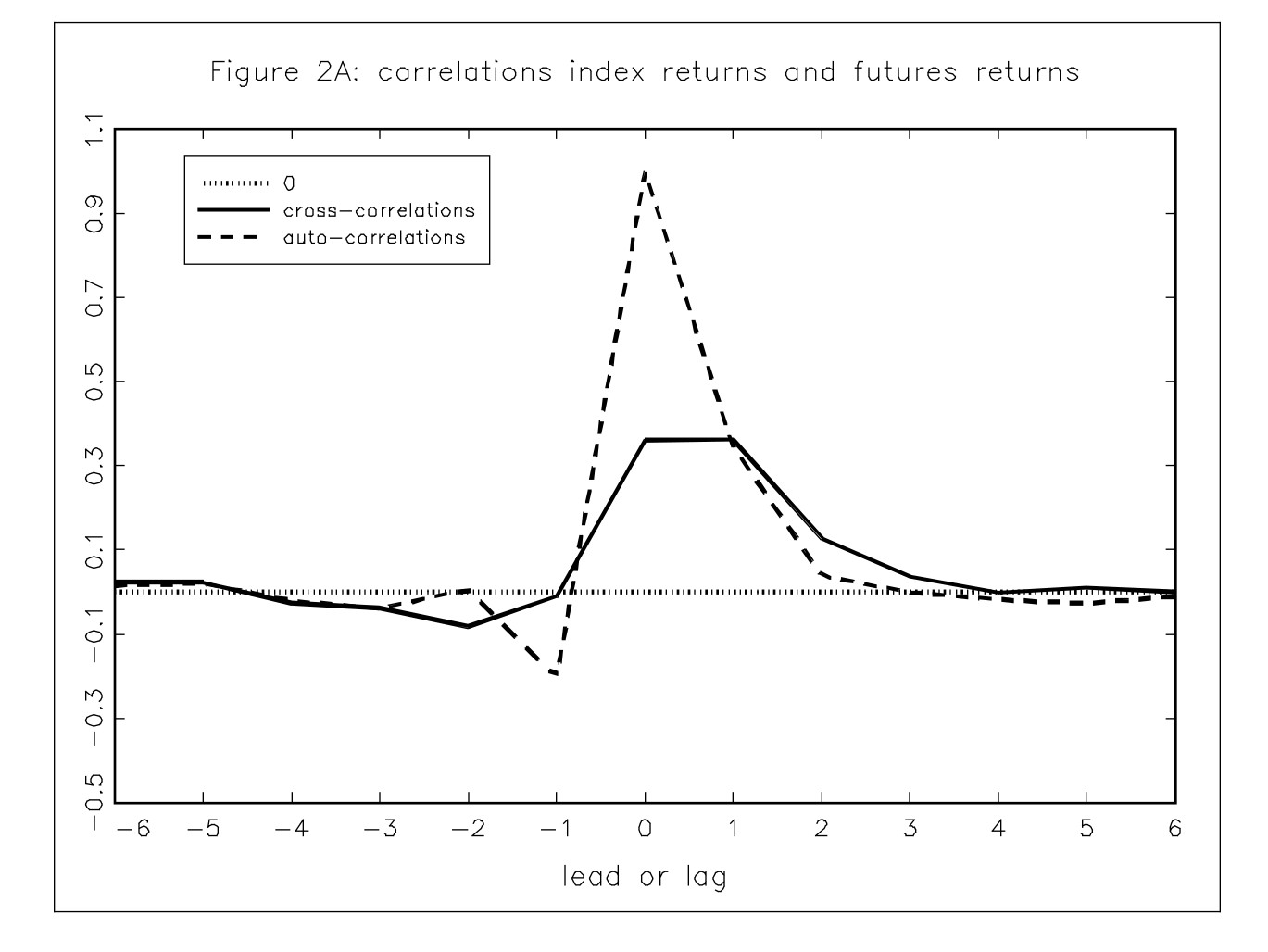
Неплохую идею для высокочастотного трейдинга подсказал Kipp Rogers в своем блоге. Идея несложная, но требующая подробного объяснения, поэтому попробую изложить ее в двух статьях.
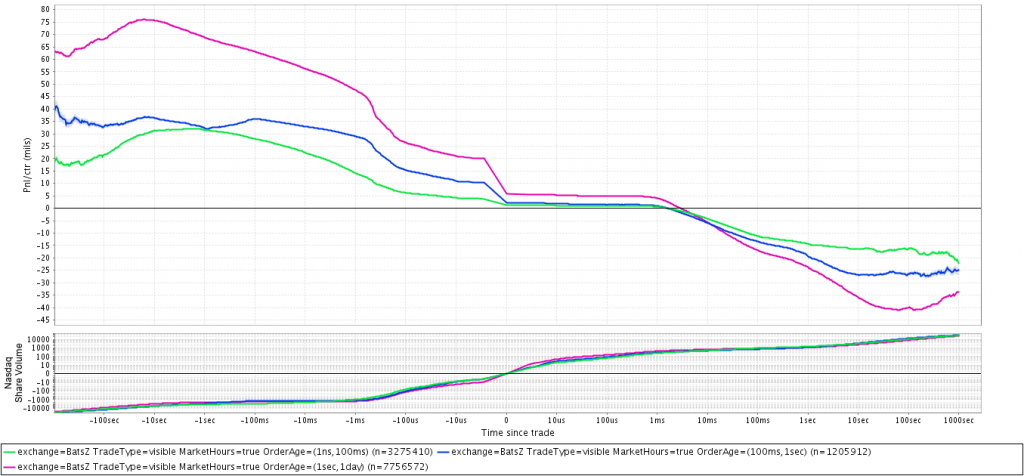
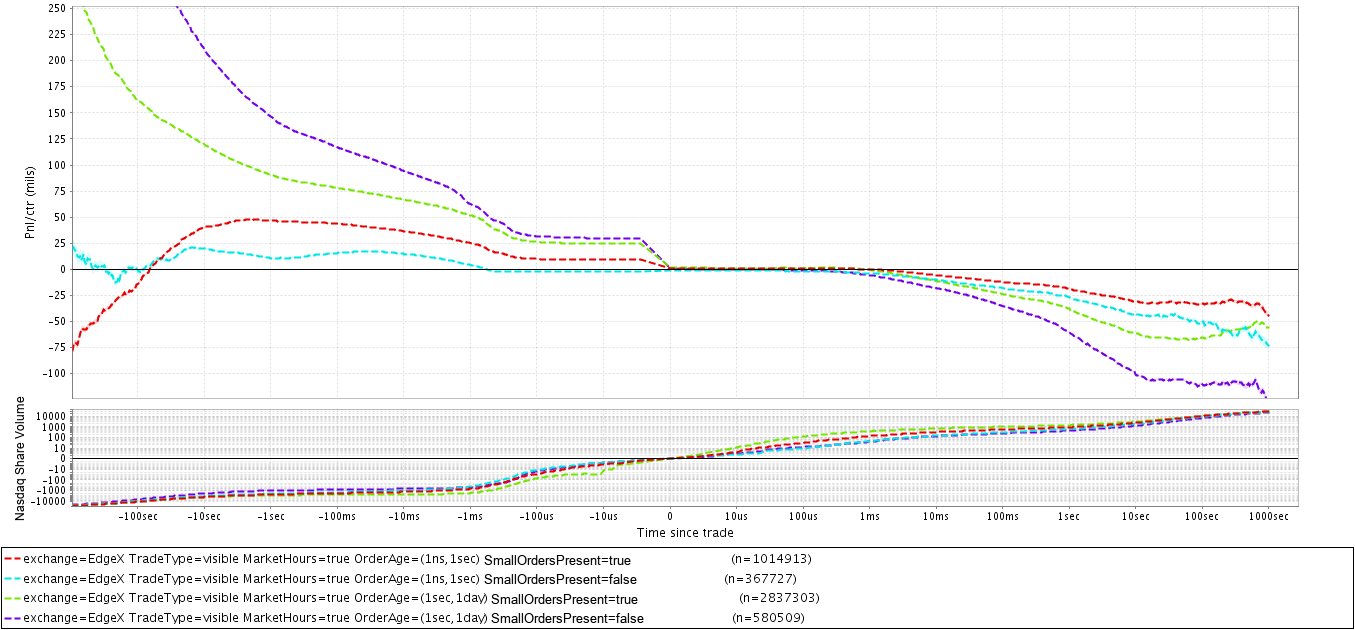
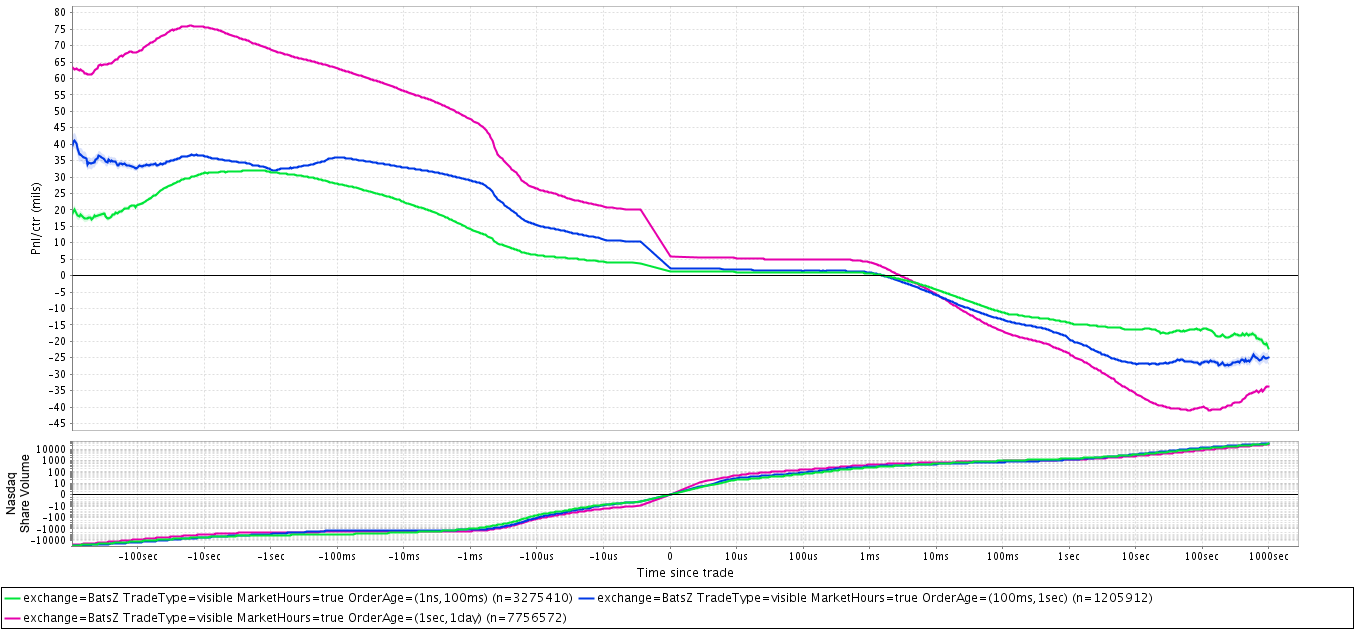
Автор предположил, что лучшее исполнение ордеров, отправленных на биржу, скорее возможно получить, торгуя с трейдерами - людьми, вручную отправляющими приказы, чем с компьютерами, то есть контрагентами с автоматическим выставлением. Высокочастотные роботы отправляют приказы на биржу только в том случае, если они видят возможность быстрого снятия прибыли или ищут наилучшую цену исполнения для больших объемов, что делает соревнование с ними очень тяжелой задачей. С другой стороны, трейдеры, торгующие вручную ( под ними могут подразумеваться и автоматические программы с медленными алгоритмами ) , выставляют приказы с большим временем жизни (до отмены или исполнения), меньше внимания уделяют мгновенной цене и, как правило, имеют идею о направлении движения цены при входе в рынок, что также дает представление о поведении их ордеров.
(далее…)


Свежие комментарии