

Ранее на этом сайте была опубликована статья по марковским моделям скрытых состояний (НММ) - часть 1, часть2, часть 3, часть 4. Мною разработана программа на основе этой публикации, с помощью которой была протестирована предсказательная способность HMM на некоторых инструментах рынка FORTS. Программа написана на языке C#, с применением сторонней библиотеки Accord.NET.
На вход программы подаются ценовые ряды фючерсов, представляющие собой последовательность свечей со значениями Open, Close, High, Low. Количество входных свечей можем задавать произвольно, эта величина является первым параметром. На выходе получаем прогноз на будущее направление движения цены. Горизонт прогноза в виде интервала, также измеряемого в количестве свечей, является вторым параметром. Третий параметр - это временной интервал самой свечи, определяется входным файлом. Исходные данные я брал с сайта Финам в виде текстовых файлов для каждого инструмента.
Модель Маркова обучается на выборке, которая получается путем деления исходного ценового ряда на две части с соотношением 70/30. Первые 70% последовательности берутся как тренировочная выборка, вторые 30% - как выборка out-of-sample, на ней проверяется устойчивость полученной модели и отсутствие подгонки. В качестве входных значений для HMM берутся логарифмические отношения Close/Open, High/Low, Close/Low, High/Close. Строится три модели Маркова для каждого из состояний - рост цены, падение, флэт.
Результаты тестирования представлены в виде следующих числовых значений:
- Probability - вероятность верного предсказания направления движения цены на горизонте прогнозирования (в процентах);
- Profit - прибыль, полученная при следовании предсказаниям модели ( в процентах от начальной цены актива);
- MaxDD - максимальная просадка по тестируемой выборке (в процентах).
Также в программе строится график кумулятивной прибыли по прогнозам в пунктах, в расчете на один контракт актива.
Итак, полученные результаты тестирования:
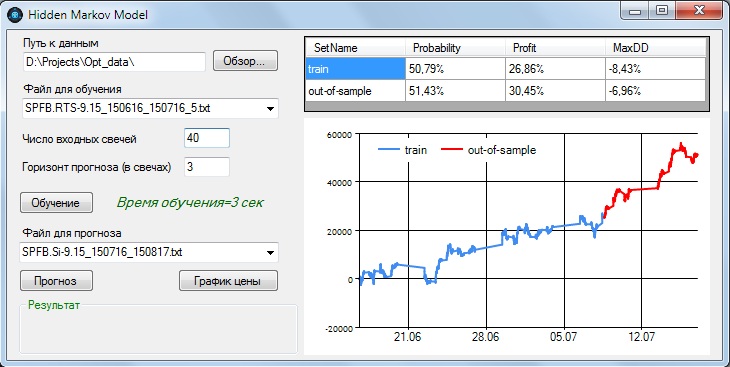
1. Фьючерс RTS-9.15, ценовой ряд на периоде 16.06.2015- 16.07.2015, интервал свечи - 5 мин.
На графике прибыли синия линия - это результат модели на тренировочной выборке, красная линия - выборка out-of-sample.
Как можно видеть, при вероятности предсказания направления цены равным 50,79% на тренировочной выборке, мы получаем прибыль в размере 26,86% примерно за 22 календарных дня. На выборке out-of-sample показатели даже лучше - вероятность предсказания 51,43% и прибыль 30,45% за 7 календарных дней. При этом максимальная просадка в обоих случаях не превышает 9%. Все указанные результаты получены при подаче на вход 40 свечей и горизонте прогноза в 3 свечи.
Посмотрим, не является ли такая производительность нашей модели результатом подгонки. Для этого проверим обученную модель на этом же инструменте, но возьмем выборку за следующий месяц - с 17.07.2015 по 16.08.2015:
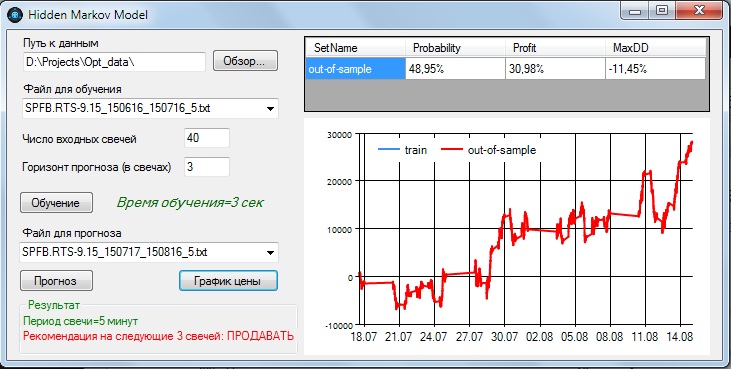
На данном отрезке вероятность предсказания упала ниже 50% и составила 48,95%. Но прибыльность осталась положительной - 30,98% за месяц. Это означает, что абсолютная прибыль при верном предсказании направления цены превышает абсолютный убыток при неверном предсказании. Максимальная просадка возросла до 11,45%.
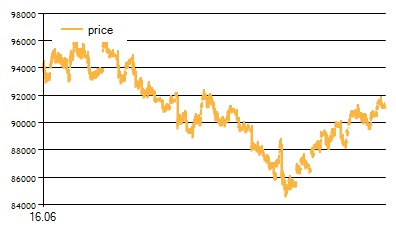
Для лучшего понимания работы модели посмотрим, как двигалась цена инструмента в рассматриваемые периоды. Для периода 16.06.2015- 16.07.2015:
Для периода 17.07.2015 - 16.08.2015:
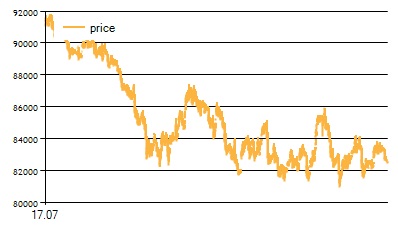
Можно отметить, что и в том, и в другом случае наблюдаются как периоды роста цены, так и периоды ее снижения, а также моменты неопределенности - флэта. В связи с этим можно предположить, что вероятность подгонки на данных диапазонах мала.
2. Фьючерс Si-9.15, период 16.06.15 по 16.07.15, интервал свечи 15 мин.
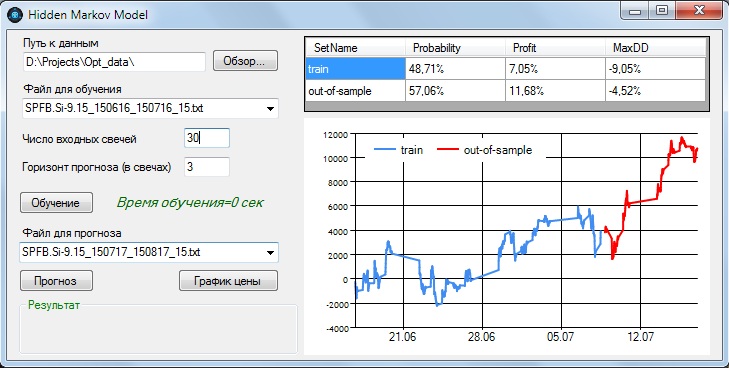
На тренировочной выборке вероятность предсказания направления составила 48,71%, прибыль - 7,05% за 22 календарных дня. На выборке out-of-sample результаты лучше - вероятность предсказания 57,06%, прибыль 11,68% за 7 календарных дней. Модель принимает на вход 30 свечей, горизонт прогноза - 3 свечи. Мы видим, что параметры модели достаточно близки к предыдущей, хотя у нас другой инструмент и другой интервал свечи - 15 мин.
Проверим, имела ли место подгонка, на периоде 17.07.2015 - 17.08.2015:
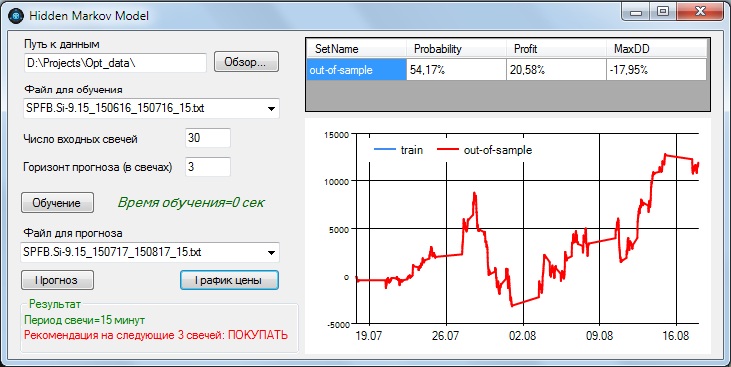
Вероятность предсказания - 54,17%, прибыль - 20,58% за один календарный месяц. Однако максимальная просадка получилась достаточно большой - почти 18%. Выводы по данному инструменту получаются неоднозначные - вроде бы сохраняется приличная прибыльность и вероятность предсказания, однако волатильность прибыли значительная.
Сделаем еще одну проверку - имитируем скользящее окно для модели. Для этого просто еще раз обучим модель с теми же параметрами, уже на втором периоде - 17.07.2015 - 17.08.2015, и результат для выборки out-of-sample (30% последней части диапазона) продемонстрирует нам эффективность скользящего окна, то есть если бы мы двигались за текущим временем, постоянно переобучая модель:
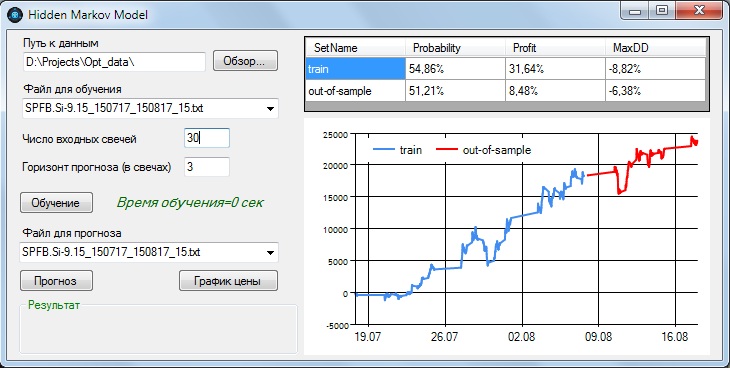
Как видим, показатели неплохие - вероятность предсказания 51,21%, прибыль 8,48% на одной неделе и просадка - 6,38%.
Проверим графики цены. Для периода 16.06.15 - 16.07.15:
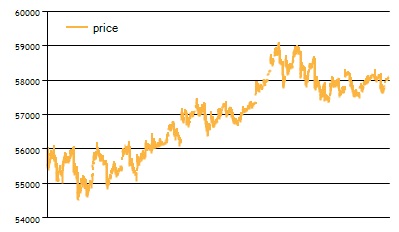
Для периода 17.07.2015 - 17.08.2015:
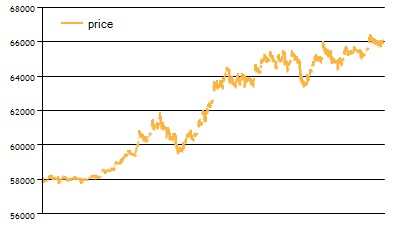
Мы видим, что графики цены похожи на обоих диапазонах - цена демонстрирует рост. Поэтому для данного инструмента вероятность подгонки остается высокой, хотя на 15 мин интервалах существуют как периоды роста, так и падения цены. Применение модели Маркова для данного варианта требует дополнительного тестирования.
Выводы. Модель скрытых состояний Маркова вполне применима для предсказания направления будущего движения цены актива, в том числе и на внутридневных интервалах торговли. Для меня была сюрпризом достаточно высокая эффективность модели, при том, что ее параметрами были исторические данные все того же ценового ряда актива. Близкие значения параметров для разных инструментов также добавляют уверенности в устойчивости модели. Однако при тестировании были отмечены и недостатки - диапазон применяемых параметров достаточно узок, и их изменение на 20-30% ( речь идет о количестве входных свечей и горизонта прогноза) может привести к резкому снижению предсказательной способности.
Повысить эффективность и устойчивость модели возможно путем добавления неценовых параметров - объема покупок/продаж, состояния книги заявок и т.п., а также правильного выбора статистического распределения этих параметров (оно используется при составлении модели Маркова, и в рассмотренном случае выбиралось нормальное распределение с нулевым средним и среднеквадратическим отклонением, вычисляемым по выборке).


День добрый, все что ниже 55% это плохо:)
Мне кажется, если поэкспериментировать в вашем примером с размером ставки, его можно как существенно улучшить, так и ухудшить.
Есть редкий случай доказательства, что в случае наличия слабых ученков (в терминах Boosting) комбинация, где каждый обладает хотя бы 55%, точность итогового прогноза может быть доведена до 99%.
Но также известен случай эксперимента, когда этот же математик посоревновался со своим ансамблем, в качестве учеников которого были деревья решений, основанные на серийном техническом анализе (стандартный набор лохомудрия от чартистов: около 20 самых любимых в тех.анализе индикаторов) с командой, выполнявшей задачи по проекту LehmanBrothers (кстати их научный руководитель - профессор Корнельского унивеситета вместе с трудящимися из Массачуссетса и Стэнфорда обещан на машинном обучении с 24 сентября по программе Майкрософт).
Правила автора Boosting формировались в результате работы алгоритма ГП, усилялись соответственно по алгоритму AdaBoost. Известны 2 его работы. Выше 50-54% WinRate он не поднялся.
Вторая команда работала в основном с очередью и книгой заявок. Соответственно это было основным. Результат был много лучше. Одни студенты тренеровались с регрессией, другие - с марковскими цепями. Что в общем-то и логично. Значимый признак - это основное.
----
Спасибо за статью. C Accord.Net знаком. Великолепно вылезанный учебный набор.
Но там у товарища нет ни одного онлайн-алгоритма. Что собственно и не нравится.
Также лично мне не известно подходящих алгоритмов с марковскими цепями со скользящим окном.
У автора только базовые алгоритмы: например у SVM только SVM 1998-го года Джона Плата. Кстати базовый SVM из этой библиотеки бил наивную нейронную сетку на задаче XOR в 200х раз! Если сделать минимальное кэширование, то SVM уже летает в разы!
Но существуют более мощные приемы восстановления зависимости с вычислительной точки зрения: рекурсивный алгоритм остается в пределах выделенной памяти + отбрасывание (прореживание) ненужных коэффициентов и входных переменных (если они не оказывают влияние на модель).
Например восстановление функции из серии y(x) = sin(x)/x + x; если x==0, то y(0) = 1 с количеством шагов 40,000 у меня на ноутбуке занимает не более 0,1 с. Безусловно входящий вектор обрабатывается в наносекунды. Матрица весов не выходит за 4 значения. Правда в бэкнраунде рекурсивный МНК.
----
Однако крайне интересно, если вы проведете дополнительные эксперименты с марковскими цепями и особенно интересны входящие переменные.
Спасибо за ваши развернутые комментарии. Да, я тоже считаю, что вероятность предсказания низкая. Так как я имею дело в основном с высокочастотными алгоритмами, там вероятность предсказания вообще должна быть на уровне 70-80%, потому что большую часть съедят комиссия и проскальзывание. По поводу более низкой частоты мне судить трудно, думаю ваша оценка в 55% близка к истине
Честно хочу сказать, мне импонирует направленность ваших статей.
55% - это устоявшееся мнение, в т.ч. с учетом названного критерия AdaBoost. Но итоговой настройке 99%))) нет необходимости реагировать на каждый ордер. Просто при настройке надо выбрать комфортные параметры.
С точки зрения теорем игры: наша вероятность на победу должна бить шансы банка.
Так как по рынку мы играем как правило в условиях сравнения проигрыша и выгрыша в конкретных шагах цены, то собственно тут все и легко отсчитать. 3 шага в убыток, допустим, 8 шагов за прибылью, комиссия 1 шаг., Т.о., ловим мат.ожидание p*8 - (p-1)*4 >0. Вот тут-то где-то 55% и находится.
Дальше, кому как комфортно. Ровно как в отношении 8 и 4.
Но что самое интересное - ведь если хорошая волатильность и ликвидность, то можно себе позволить и WinRate ниже 50% или вероятность, но мы должны иметь хороший потенциал.
Таким образом, у нас получаются текущие шансы и потенциальные. Вот вам и следующее направление ранжирования решений. Среди равных текущих шансов нас интересует максимальный потенциал. Собственно нисколько не сложнее идей Кейнса.
В принципе математика элементарна. Но несколько затратна, в случае ранжирования и поиска. Поэтому собственно меня интересуют онлайн алгоритмы.
Но марковские цепи - это классика. Я действительно пока не придумал кроме как пересчет окна для включения их в качестве голосующего ученика. В целом предсказательность не хуже и не лучше. Все около 3-5% гуляют.
В общем, не отбрасывайте. Может можно рассмотреть как некую систему уравнений, где надо найти минимум ошибки...и рассматривать как рекурсивный МНК. Пока не укладывается.
Мне кажется, в обоих примерах все таки и iiiS и ооS на обоих инструментах присутствует тренд - на ri даунтренд , на si - аптренд . Есть ощущение, что модель уловила эту закономерность и выдает преимущественно предсказания по тренду, и соответственно если тренд на следующем периоде поменяется- то модель сломается. Этим свойством- выдавать предсказание в сответствии с трендом периода обучения грешат большинство моделей машобуча
Не забывайте, что интервал свечей - всего 5 и 15 мин. Цена выглядит так в полном диапазоне, если посмотреть ближе, по дням например, вы увидите там полный набор аптрендов и даунтрендов в разных сочетаниях. Тем более на РИ даже в месячном диапазоне видны достаточно продолжительные участки как роста, так и падения
Но в целом - судя по графику тренд присутствует - его и ловит модель .Попробуйте найти 2 периода где не совпадают тренды - и я думаю, что предсказательная способность модели будет неприемлема. Буду рад ошибиться в прогнозе- но на эти грабли наступал сам и многие другие
Я согласен, что при таких входных параметрах, взятых из того же ценового ряда, модель вряд ли будет робастной на длительном промежутке времени. Но, как правильно заметил Алексей в комментарии ниже - нужно искать правильные признаки
Грешат не модели, а признаки. модель дает только то что она и предполагает.
Серийный ценовой анализ никому еще никогда ничего не дал. Если уж Yoav Freund и Robert Schapire не вытянули никак, то куда уж дальше? Причем как сам по себе Boosting в различных вариациях, так и ГП, ровно как и HMM и не только - каждый сам по себе вполне справляется с распознаванием речи, изображений и т.д. Так что обратно на природу за естественными признаками. Это самое дорогое.
С этим трудно спорить 🙂
Модель, кстати , справилась прекрасно - уловила направление тренда, несмотря на шум, и дает прогноз , исходя из этой закономерности
Спасибо что мы друг друга поняли. Конечно, предполагается, что мы заранее понимаем сферу применения моделей. Ну, а автору сайта спасибо за творческий порыв. Однако хотелось бы напомнить, что отец броуновского движения т.Башелье интересовался спекуляцией и диффузией заявок на покупку/продажу облигаций и умудрился обогнать в этом даже тов.Эйнштейна. Сколько разные эконометристы не сжимали/разжимали в простые алгоритмы индексы и бумаги американского рынка за всю доступную историю, так ничего и не вышло.
Так что анализировать серийную зависимость по сделкам бесполезно. Хотя заодно придумали сумасшедшие алгоритмы, например в одной исследовании обнаружил загрузку файла данных изначально имевшего размер 160 гб с данными по всем тикам за 20 лет по 60-ти бумагам, по-моему, сжатый более чем в 4х-8х раза буквально в пределах секунды по каждой бумаге (очевидно что в пределах RAM) сравнению со 140 секундами ascii файла изначально. И так по каждой операции.
---
Вообще говоря, мне так кажется, что вы все же занимаетесь подгонкой. Ну, невозможно из предущих сделок ничего собрать. Вот и 50-55% это просто недостаточно для принятия решения. Причем скорее всего вы там подкручивали периоды внутри серии, вот и получили 50-51%. Ну чем приблизим - по большому счету уже есть ответ: любую серию можно представить комбинацией полиномов любой степени. Ну вот в районе 500-й) ответ может быть и без ошибки.
Надо искать комбинацию, которая даст комфортную оценку. Есть классика денежный рынок/облигации - фондовый. Не сомневаюсь, отсюда очень сильные взаимосвязи. Доля денежного рынка (я туда отношу и облигации и межбанк и конверсионные операции) далеко за 90% по оборотам. Акции и индексы на них это всегда спекуляция - в этом и тов. Грэхем - автор фин.анализа перестал что-либо понимать. По поводу источника финансирования - это для тех кто видит горизонты за несколько лет.
Поэтому ну как ни крути на языке родных берез надо опускаться до подтвержденного ставкой спроса и предложения.
Валюта своя природа, но встречаемся в стакане с той же диффузией.
и т.д. ит.п.
Собственно ряд статей у вас вполне об этом на сайте: метрики, агенты, то есть решаем основную теорему покера: "играем в случае, когда наша комбинация лучше"
Спасибо что мы друг друга поняли. Конечно, предполагается, что мы заранее понимаем сферу применения моделей. Ну, а автору сайта спасибо за творческий порыв. Однако хотелось бы напомнить, что отец броуновского движения т.Башелье интересовался спекуляцией и диффузией заявок на покупку/продажу облигаций и умудрился обогнать в этом даже тов.Эйнштейна. Сколько разные эконометристы не сжимали/разжимали в простые алгоритмы индексы и бумаги американского рынка за всю доступную историю, так ничего и не вышло.
Так что анализировать серийную зависимость по сделкам бесполезно. Хотя заодно придумали сумасшедшие алгоритмы, например в одной исследовании обнаружил загрузку файла данных изначально имевшего размер 160 гб с данными по всем тикам за 20 лет по 60-ти бумагам, по-моему, сжатый более чем в 4х-8х раза буквально в пределах секунды по каждой бумаге (очевидно что в пределах RAM) сравнению со 140 секундами ascii файла изначально. И так по каждой операции.
---
Вообще говоря, мне так кажется, что вы все же занимаетесь подгонкой. Ну, невозможно из предущих сделок ничего собрать. Вот и 50-55% это просто недостаточно для принятия решения. Причем скорее всего вы там подкручивали периоды внутри серии, вот и получили 50-51%. Ну чем приблизим - по большому счету уже есть ответ: любую серию можно представить комбинацией полиномов любой степени. Ну вот в районе 500-й) ответ может быть и без ошибки.
Надо искать комбинацию, которая даст комфортную оценку. Есть классика денежный рынок/облигации - фондовый. Не сомневаюсь, отсюда очень сильные взаимосвязи. Доля денежного рынка (я туда отношу и облигации и межбанк и конверсионные операции) далеко за 90% по оборотам. Соответственно решение безарбитражного равновестия спот/фьючерс, облигация/позиция в валюте с учетом некоего аналога эластичности спроса/предложения облигация/валюта и уже потом акция и производная на нее на макроуровне. Акции и индексы на них это всегда спекуляция - в этом и тов. Грэхем - автор фин.анализа перестал что-либо понимать. По поводу теоретического источника финансирования - это для тех кто видит горизонты за несколько лет. По крайней мере ни одна модель тов. Джона Мэривзера, бывшего как известно пионером прикладных численных финансов, крайне результативным в деривативах на облигации, в акциях не только не дала результата, но и привела к банкротству LTCM в 1999 г.
Поэтому ну как ни крути на языке родных берез надо опускаться до подтвержденного ставкой спроса и предложения в случае, если мы "блуждаем" среди других игроков.
Валюта своя природа, но встречаемся в стакане с той же диффузией.
и т.д. ит.п.
Собственно ряд статей у вас вполне об этом на сайте: метрики, агенты, то есть решаем основную теорему покера: "играем в случае, когда наша комбинация лучше" - ведь кто-то должен же оплачивать свой интерес узнать, а что будет дальше.
Не очень понятен переход от HMM к реальной модели. Трейдинговая модель - это условия на вход, выход и стоп лосс. Я так понимаю, что раз "горизонт прогноза" 3 свечки, то и модель всегда выходить после 3х свечек независимо от прибыльности или убыточности трейда. Т.е. стоп лосса нет в принципе, выход всегда независимо через 3 свечки?
Да, выходим после 3 свечей, но если сигнал в ту же сторону - остаемся в позиции. Это все только нужно для теоретического подсчета вероятности предсказания модели, в реальных торгах, конечно, можно применять стоп-лосс, тем более что система получается импульсной.
Сложности с входными параметрами, imho, возникают от недостатка иформации. В физике нет проблем с входными параметрами. В книгах по механике есть подходящие входные параметры, т.к. они любую систему описывают используя коордиты точки, частицы и т.п. и ничего кроме координат для полного описания не надо, все из них получается.
Все системы ведения боевых действий работают в условиях недостатка информации и именно в этих условиях принимаются решения.
Весь этот сайт затеян в попытке найти методы добычи информации, и собственно саму информацию. Строят модели, в попытке найти устойчивые закономерности. Модели претерпевают изменения, и продолжают дальше искать искать и искать....
Вероятностно предсказать с хорошим уровнем прогноза можно только независимые события, с коррелированными событиями сложнее.
Кто-нибудь знает как в физике задается состояние системы ?;-)
Я так понимаю, что обучение проводилось на размеченных данных? Я не увидел, в accortd net обучение модели без учителя, поправьте, если это не так. Если обучение было с учителем, то как готовили данные? Т.е. что было в качестве входных параметров? Сколько примеров было использовано для обучения?
Спасибо.