
По просьбе одного из читателей блога прогнал тесты инструмента SPY в моей программе, использующей модель Маркова для предсказания направления рынка. SPY- это биржевой символ фонда, повторяющего движения индекса S&P500, торгуется на бирже NYSE. Тестирование производилось на периоде от 01 июня 2015 года до 25 ноября 2015 года. Размер тренировочной выборки - 70%, выборки out-of-sample - 30%. Вот что получилось в итоге, для различных интервалов дискретизации:
1. 60- минутные бары:
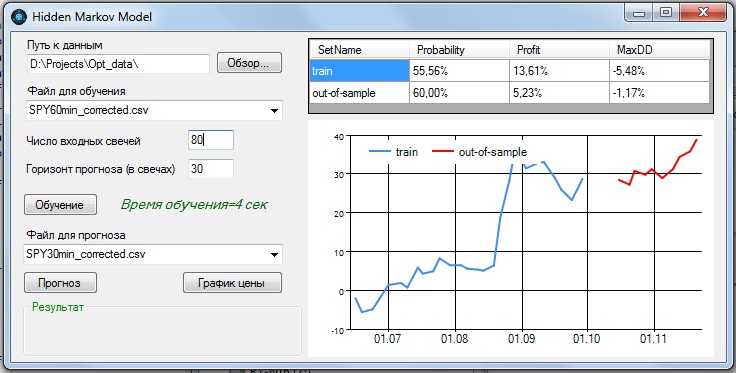
Наилучшие показатели получились при параметрах:
- - количество входных баров = 80;
- - прогноз на 30 баров вперед.
2. 30-минутные бары:
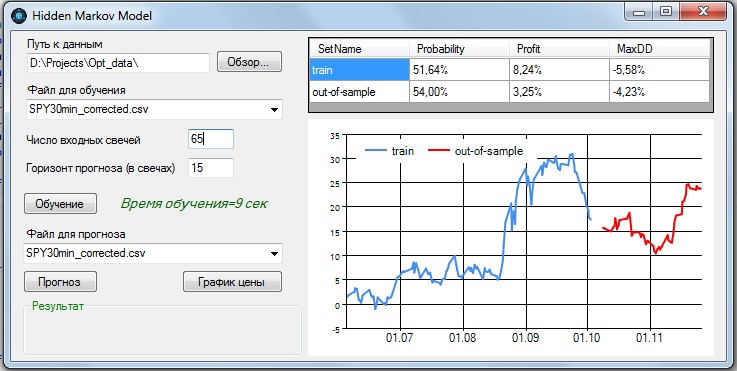
Наилучшие показатели получились при параметрах:
- - количество входных баров = 65;
- - прогноз на 15 баров вперед.
3. 15-минутные бары:
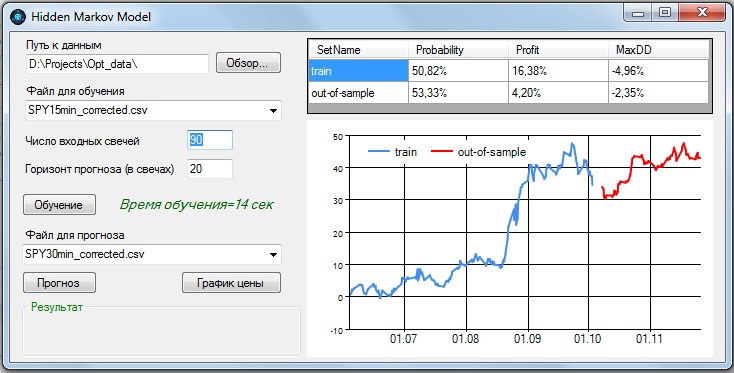
Наилучшие показатели получились при параметрах:
- - количество входных баров = 90;
- - прогноз на 20 баров вперед.
На интервалах менее 15 минут положительных результатов получить не удалось.
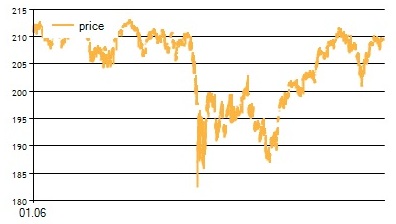
В заглавии поста представлен график значений SPY за исследуемый период.
Как видно из графика, исследуемый отрезок очень волатильный, есть и восходящие тренды, и нисходящие, флэт, и даже определенный обвал цены. Тем не менее, модель показывает неплохие результаты даже на таком сложном участке.
Можно сделать вывод о возможности предсказания SPY с помощью модели Маркова на интервалах дискретизации от 15 мин, используя исторические данные от 22 часов до 80 часов, с горизонтом прогноза от 5,5 часов до 30 часов.


а сколько было сделок и учитывался ли спред?
Решение применяется на каждом интервале дискретизации. Сделок будет, конечно, меньше, потому что, если прогноз совпадает с текущей позицией, ничего не предпринимается. Спред не учитывался, на таких больших интервалах он не должен сильно влиять. Программа не боевая, показывает только теоретический прогноз, но на барах 15-60 мин должна быть близка к реалу
Серийный анализ цен бесполезен. Ни одним алгоритмом ни ни одном компьютере мира не удалось до сих пор сжать ни одного ценового ряда. Все эконометристы и эконофизики об этом постоянно говорят. Пахнет подгонкой.
Вот анализ коинтеграциии или просто связи разложенных по моделям ценовых изменений инструментов вызывает большее доверие.
Но анализ главных компонент плюс регрессия по изучаемым признакам с логичной физической подосновой уже давно убили марковские цепи следом за нейронными сетями по производительности и точности.
Да я с этим не спорю, меня самого удивляют результаты. Подгонка, конечно, очень вероятна, но параметры устойчивы в некоторых пределах, что навевает некоторые вопросы, тем более на такой волатильной выборке. В-общем, пока в бою не попробуешь, не узнаешь. Но я бы не рискнул на сильно больших интервалах, лучше на наших фьючерсах пробовать - там положительный результат получался на более высокой частоте.
Ну если уж такое дело, в научных целях сравнили бы интереса ради с броуновским движением, хестоновским или бейтсовским) процессами.
Если уж дойти до полного маразма, можно сделать какой-нибудь метод, который бы динамически создавал модель хоть из 100 диф.уравнений.
Вопрос, что вы подаете HMM. Вот тут самое интересное, если засунуть ту же волатильность или ее изменение вместе с ценовым изменением, что окажется сильнее?
Читая как-то 2 года назад топик CudaFy - обертка под .Net над GPU CUDA, был немного удивлен "глубиной" подхода одного товарища. Он пытался обучить нейронную сеть, которой на вход подавалось умопомрачительное количество параметров, сфабрикованных из нескольких валютных курсов. Вопрос его к разработчикам библиотеки был, почему несмотря на долгое обучение не по одному дню, ошибка не падает.
Тут, наверное, анализ главных компонент и даст ответ: что ни делай, все суть преобразования базовой серии и значимости не имеет.
Единственное что кажется логичным и доступным из ценовой серии: объем, направленность, волатильность. Но все же подтвержденная ставка в форме заявки вроде как посильнее.
Поэтому тех.трюков-то не так много: шкалирование и небольшое преобразование ценовой серии, имея в виду, небольшое смещение или совместное использование смещенных данных, как параметров. HMM нужно входное и выходное состояние. Для классификации спама - это безусловно один из базовых классификаторов.
Вы что на вход вставляете?
На вход подаю разные отношения между OHLC, то есть некоторая зависимость от волатильности во входном сигнале присутствует
Я имел в виду делаете ли вы сравнение состояния в периоды -1, -2, - 3
Допустим изменение за 1, период, за 2, за 3, максимальный прирост за 3, прирост без падения, т.е. ставка 4/1.
Все же кажется, что скользящее среднеквадратичное отклонение с разными периодами можно включить.
Но тут больше уже ничего и не добавить.
--
Я все же склоняюсь к регрессиям волатильности на прогнозируемый период, поведения отдельных переменных, например, аналогичных названным. Анализ чуть легче осуществлять. Потому что в классификации (HMM - это классификация) задача должна быть все же формулируется как 0 или 1 (конечно, можно и многоклассовую осуществить).
В случае регрессии пространство видно шире. Безусловно в классификации можно нарисовать РПХ - рабочая характеристика преемника (ROC respone operator curve), куда нанести множество состояний при разных входных параметрах и сразу видна пригодность, то есть где площадь больше - над или под 45 градусов. Но это чуть из другой оперы.
Но все же как зависимость от некоторого состояния (или состояний) легче увидеть и выбрать комфортный профиль на регрессии легче.
Конечно, классификация и регрессия идут рука об руку.
Но мне не очень нравится узкая постановка: вероятность 4/1, 5/1, 8/3, на каждую из которых нужно вытаскивать отдельный классификатор.
Просто построение регрессии дает график зависимости. И двигаясь по нему по каждой переменной можно создавать итоговый ансамбль с итоговыми характеристиками прогноза, придавая вес каждой отдельной регрессии (или фильтру из обработки сигналов).
Все же я склоняюсь, что классификации должны подпадать только признаки - играют или нет, шкалирование и группировка и все.
Дальше нужно непрерывное поведение. Но в случае оптимизации регрессии у признака просто появлятся вес в виде нуля и все тут. Собственно анализ главных компонент эту функцию не менее шикарно выполняет.
Поэтому мне кажется что классификация чуть уже в своем применении.
Ведь допустим как сравнить две стратегии и которую лучше выбрать? Например, берем и сравниваем, что обе дают шансы на 2 периода прогноза 9/2 (9 выигрыш, 2 проигрыш).
Классификатор выкатит два раза да.
А если посмотреть на график, то там лучше ясна зависимость: монотонность, линейность или прогрессия и т.п. в конце концов, если хорошая модель, то она нам даст хорошую возможность оценивать, то я бы выбрал в том числе и там где потенциал роста повыше. Допустим мы сравнили только два шага, а если на 3-м шаге идет расхождение и дальше только нарастает. И тут достаточно было бы сравнить только 2 средних значения на нескольких периодах и подтвердить их визуально.
Вы скажете, а давайте сравнивать где среднее значение и ту стратегию и выбирать: задача классификатора. Да, согласен, но сначала нужна регрессия.
У меня такой подход взят за основу, а HMM я только решал в качестве задачки на классификацию спама. Да, есть некоторое количество размышлений и в научных статьях в том числе по книгам заявок.
Но есть несколько аргументов - а как осуществить "забытие", по аналогии со скользящим окном?
То есть напрашивается вывод- сделать расчет заново от вновь поступившего значения.
Далее HMM требуется хранить все виды соотношений. В случае регрессии мы храним только набор весов под каждый признак.
Точнее не на каждый признак а на каждый член регрессии, ну а в случае голосования вес на каждый признак